How to Run ChatGPT-Style AI on Your Computer: No Internet Needed!
Run Large Language Models offline. Discover how to set it up for private, local use without the need for cloud services.


Large Language Models (LLMs) like ChatGPT have become immensely popular, transforming the way we interact with technology. Typically, these models are accessed using a browser and via the cloud, requiring an internet connection and sending your data to remote servers for processing. But what if you could run a similar AI model entirely on your own computer, without needing the internet?
Running LLMs locally, is now possible with tools like Ollama or LMStudio. This provides enhanced privacy—when running models locally, all data remains on your machine, reducing the risk of exposing sensitive information to external servers. Additionally, you'll not be subject to bandwidth issues on external services, as there’s no need to rely on cloud services. In this guide, we’ll explore how to get started with running AI models on your own computer, with no internet required.
How quantisation makes this possible
In the past, running an LLM like ChatGPT needed an exceptionally powerful computer, typically reserved for data centres or cloud platforms. This was because these models were enormous in size and complexity, requiring vast computing power and memory to function. Imagine trying to run the latest high-end video game on a very old laptop—it just wouldn’t cope with the demands.
To understand how you can run powerful LLMs on your own computer, it's helpful to know a little bit about quantisation. Don’t worry, it’s not as complicated as it sounds!
Quantisation is a process that makes big, complex things smaller and simpler to handle. Here’s a simple way to think about it: imagine you have a very large set of numbers—this could represent anything, like colours in a picture, sound levels in music, or, in our case, the data inside an AI model. Normally, working with all these different values would require a lot of computer power, like trying to carry a heavy load all at once.
Quantisation helps by grouping these large numbers into smaller sets of representative values. It's like reducing the colours in an image from millions of shades to just a few key ones, but still keeping the image looking mostly the same.
Similarly, when a model is quantised, the precision of the parameters in the model is reduced. For example, instead of representing the weights of the model with 32-bit floating-point numbers (which are very precise), quantisation might use 16-bit or 8-bit integers. This results in a smaller model that takes up less memory and requires less computational power, but the actual number of parameters (weights and biases) remains the same.
How to run an LLM on your computer
If you’re curious about how open-source language models stack up against closed-source counterparts like ChatGPT, start by checking out the web-based tool LMArena.ai. It offers a straightforward way to compare various models side by side, although the user interface could benefit from some improvements.
For those interested in running an LLM on your own computer or server, there are a few user-friendly options that also keep your data private.
If you don't have much technical expertise and want to run open source models on your computer, LM Studio is your best bet. Simply download the application and follow the instructions and you should be fine. If you get stuck, there is no shortage of tutorials on Youtube to help out.
If you’re comfortable with a deeper technical setup, want top performance, plan to run models on a server, or need to handle or compare multiple open and closed-source models at once, consider using Ollama. It’s designed to give you maximum flexibility and power under the hood.
Before proceeding with the installation of Ollama, I recommend reading the section A more user-friendly interface below, which presents a slightly more technical method but results in a much more intuitive and user-friendly experience.
- Download Ollama: Visit the Ollama website and download the appropriate version for your operating system (Windows or macOS).
- Install the software: Unzip the downloaded file. For Windows, follow the on-screen instructions to complete the installation. On a Mac, it is recommended to move the unzipped application file to your Applications folder.
- Launch Ollama: Open the app to start the local server in the background.
- Launch an LLM: Then open the Terminal app on a Mac (type command-shift-space and Terminal) or Command Prompt on Windows (type "cmd" in the Windows search bar). Choose an LLM from this list. As of the time of writing, Meta's Llama 3.2 with 3 billion (3B) parameters strikes an excellent balance between being lightweight and offering strong performance. Other interesting models that require a bit more compute power include Google's Gemma 2 (7B) and Mistral (7B). We start this LLM using this command, which will download the weights of the model when using it the first time:
ollama run llama3.2Note: You should have at least 8 GB of RAM available to run the 7B models, 16 GB to run the 13B models, and 32 GB to run the 33B models.
- Use the LLM: You can now interact with the LLM in the terminal.
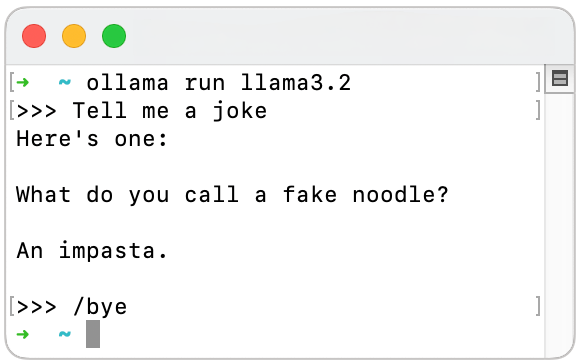
Lastly, to quit the LLM, type /bye or Control-d.
You can find more commands here.
For those interested in accessing a wider array of models, Ollama can also pull any GGUF model from the Hugging Face platform. After enabling Ollama under your Local Apps settings, you can do this as follows:
ollama run hf.co/{username}/{repository}A more user-friendly interface
The command line isn’t the most user-friendly interface, and I anticipate that more accessible standalone apps, which don't require any command line use, will be available soon. In the meantime, for those who are comfortable with the command line, there are excellent web-based interfaces that offer a much more intuitive experience in the browser, while connecting to Ollama’s local API server in the background.
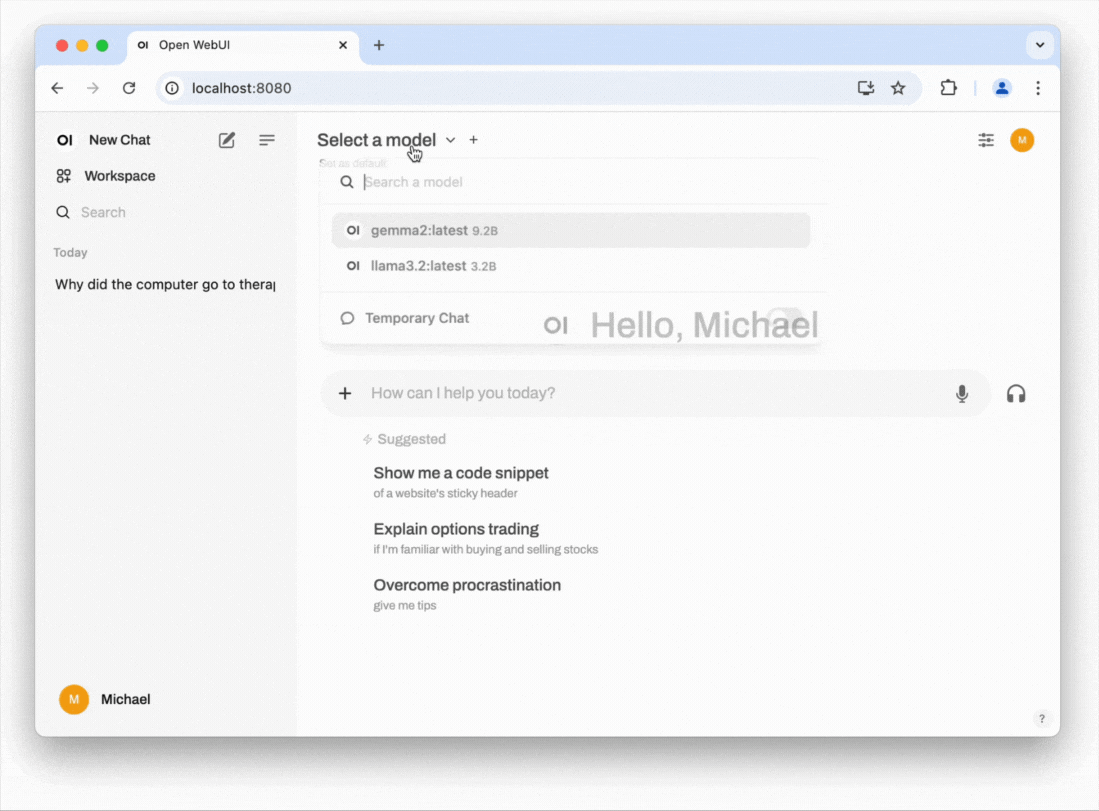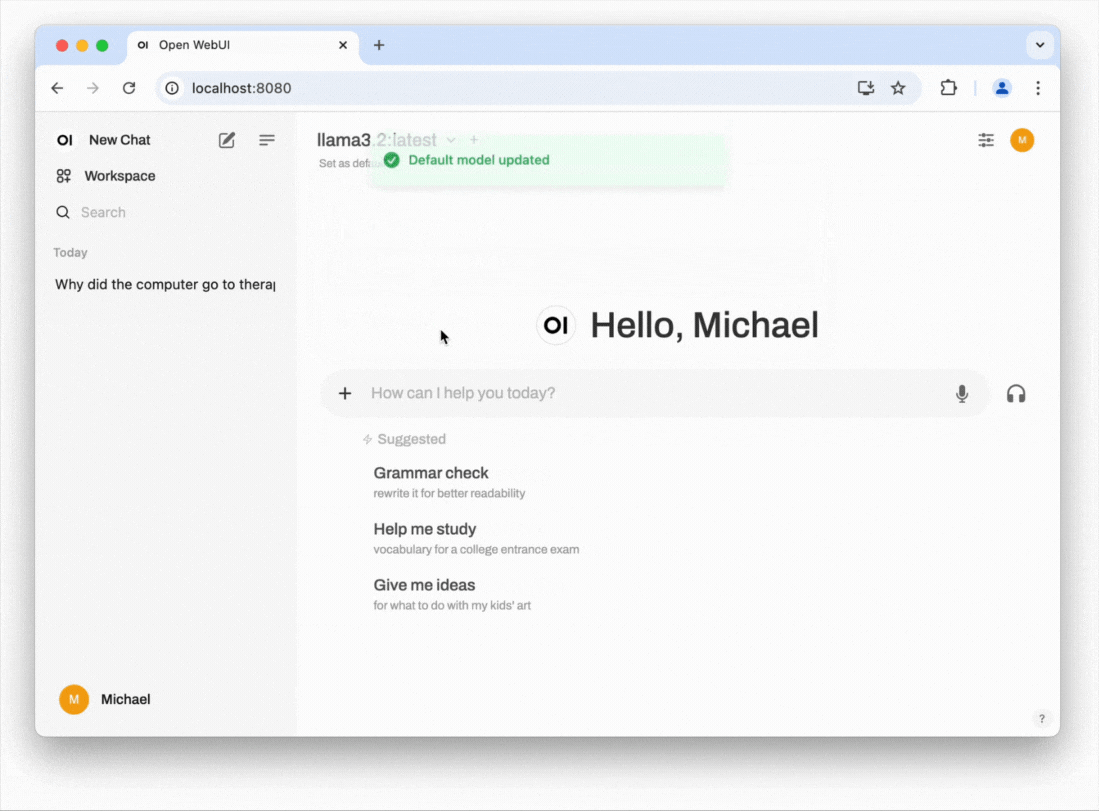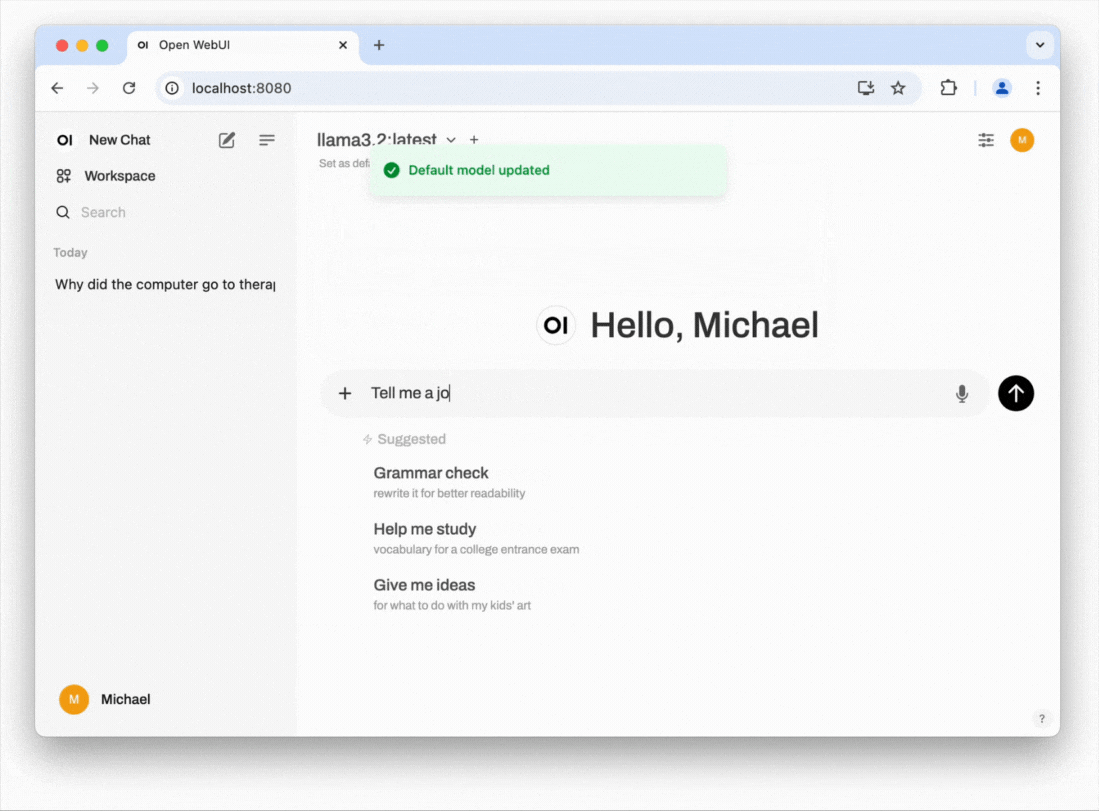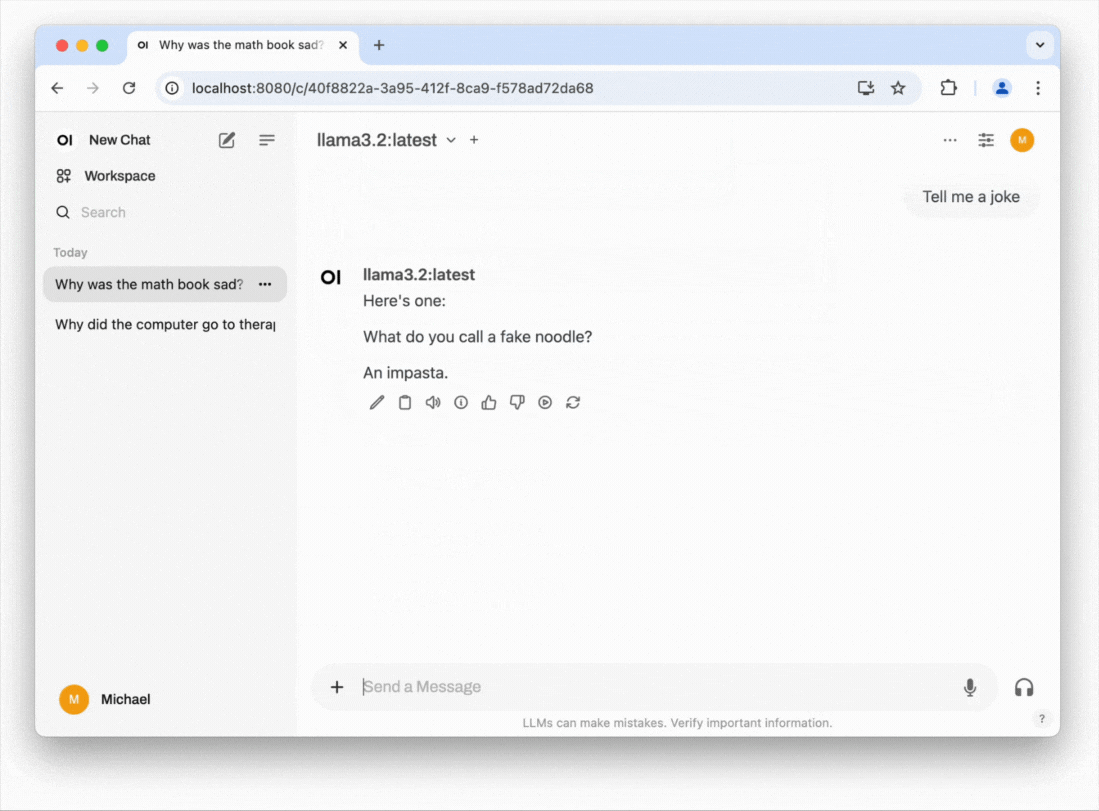
In the example below, we use Open WebUI, a project that provides a ChatGPT-like interface. It can connect to your local LLM, as well as ChatGPT (via an API subscription) and other external services, allowing you to easily switch between your local LLM and external providers.
There are several ways to install it with the easiest (but not most performant) one being the following:
- Install Docker: Download the desktop app from the Docker website and install it.
- Open Docker: Open the Docker app.
- Install Open WebUI with bundled Ollama support: Open the Terminal app on a Mac (type command-shift-space and Terminal) or Command Prompt on Windows (type "cmd" in the Windows search bar). Run one of the below commands.
If you have an NVDIA GPU installed:
docker run -d -p 3000:8080 --gpus=all -v ollama:/root/.ollama -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:ollamaIf you don't have NVDIA GPU installed (applies to most computers including Apple laptops) or if you are not sure:
docker run -d -p 3000:8080 -v ollama:/root/.ollama -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:ollama- Open your web browser: Navigate to
http://localhost:3000/- Register a user: This will create an entry in your local database for you to sign in and protect your data.
- Install the LLM locally: Open the model selection dropdown. From there enter an LLM from this list. As of the time of writing, Meta's Llama 3.2 with 3 billion (3B) parameters strikes an excellent balance between being lightweight and offering strong performance. You can download this model by entering llama3.2.
Note: You should have at least 8 GB of RAM available to run the 7B models, 16 GB to run the 13B models, and 32 GB to run the 33B models.
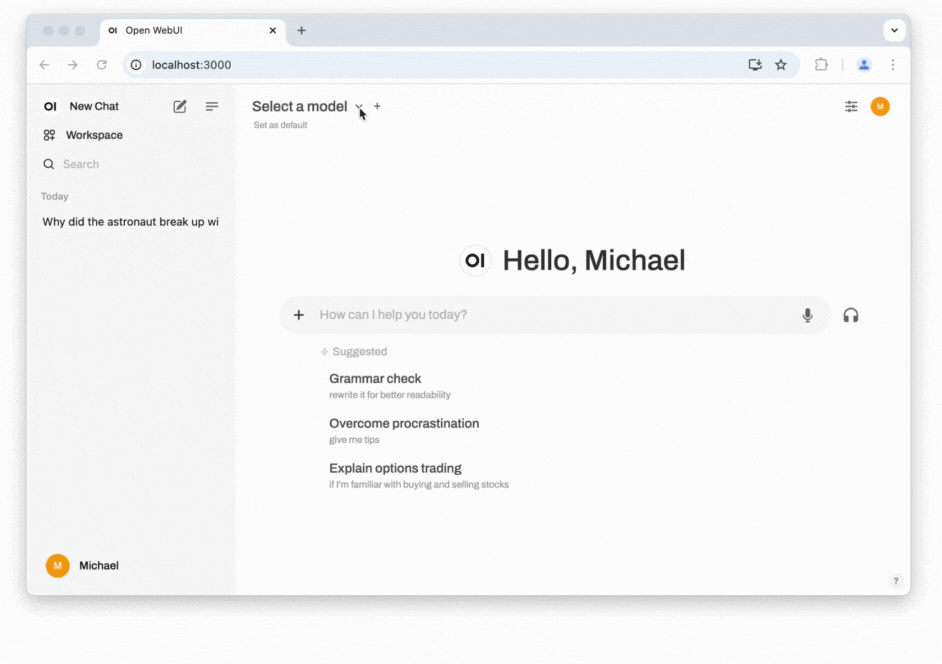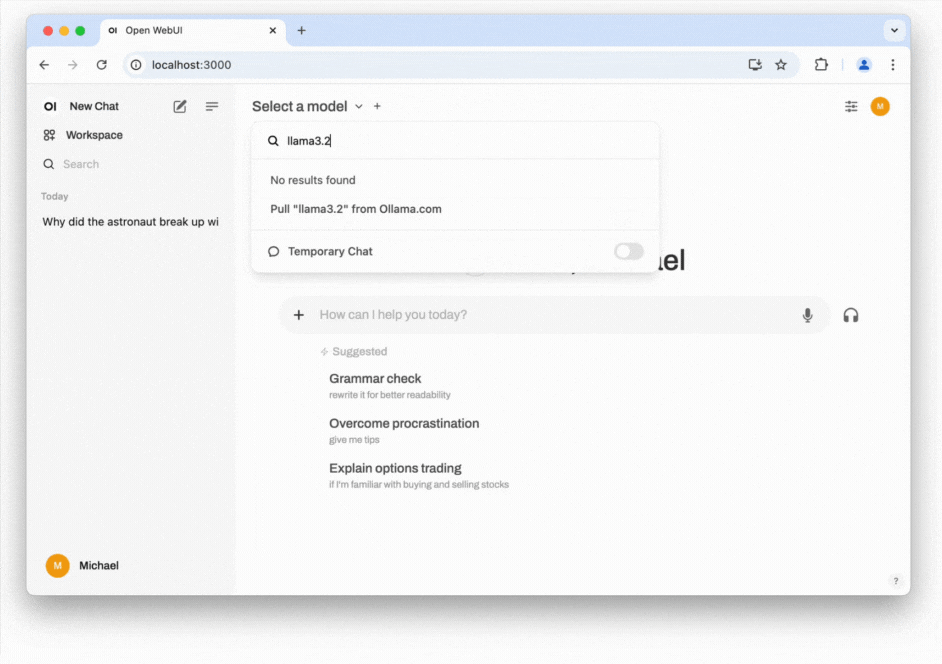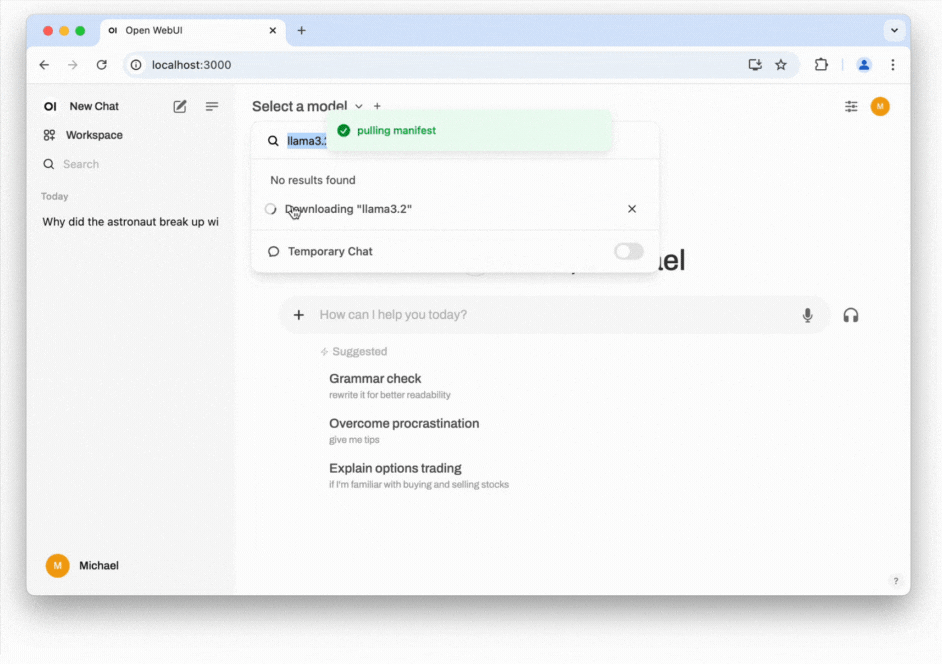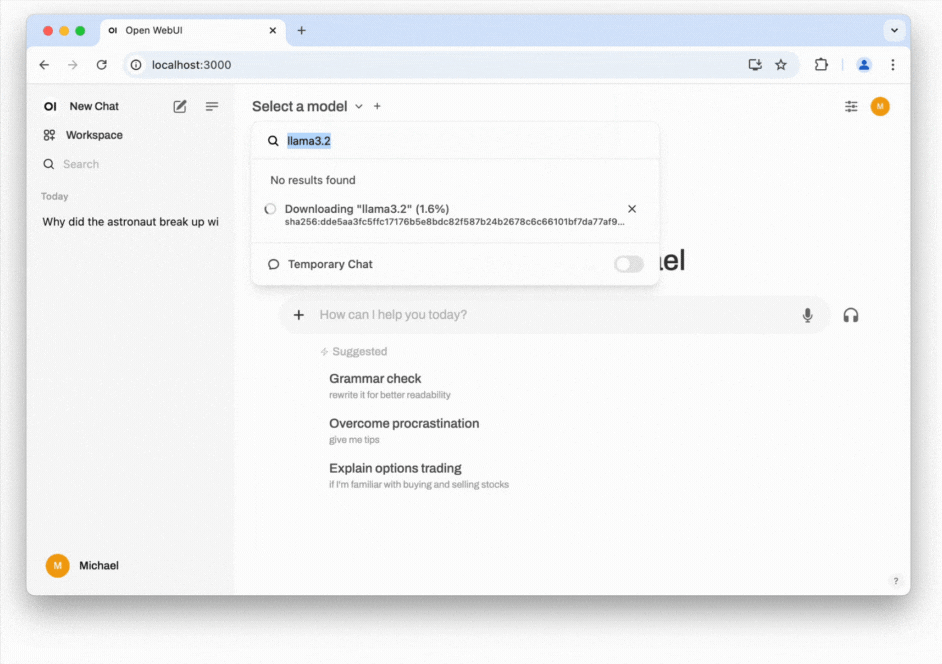
- Start chatting: You should now be able to select the model and start chatting. Click on Set as default to not always have to select the model when starting a new conversation. If responses are slow, consider selecting a model with fewer parameters or adjusting the amount of RAM allocated to Docker. You can do this by navigating to the Settings cog in the Docker app, then selecting Resources. A common cause of slow performance is Docker itself, as it introduces overhead and might not use resources efficiently when handling next-token prediction, which can be noticeable when compared to running Ollama directly in the terminal (see the previous section: How to run an LLM on your computer). If you are comfortable with the command line, you may also want to explore alternative installation methods for Open WebUI, such as using Python's pip.
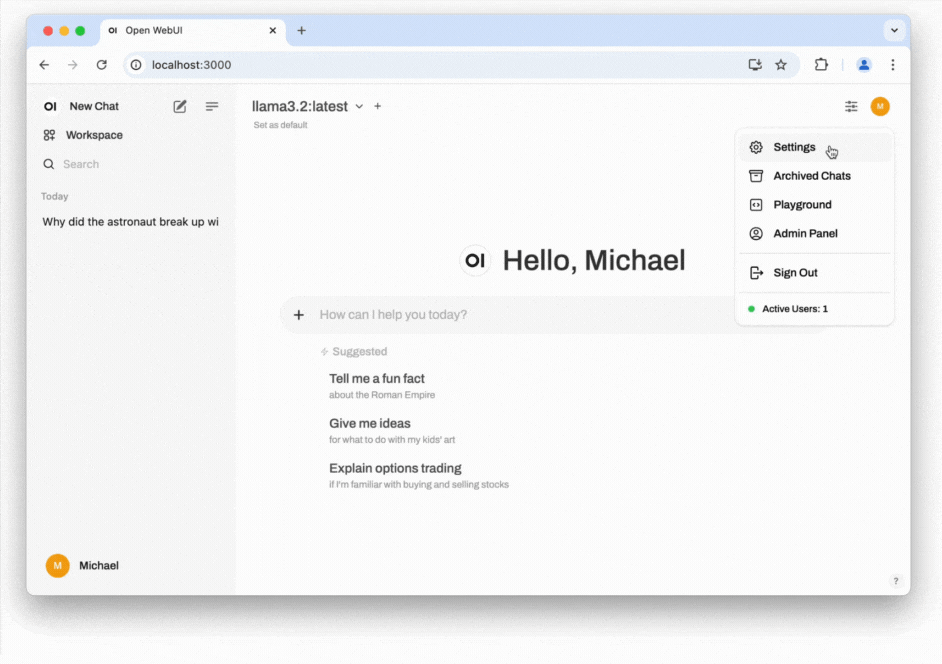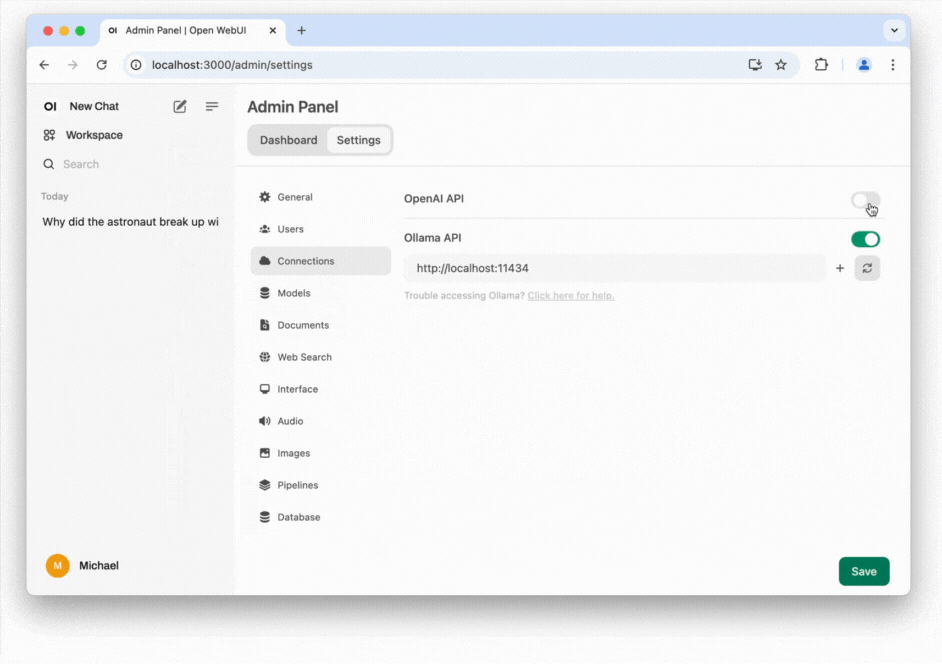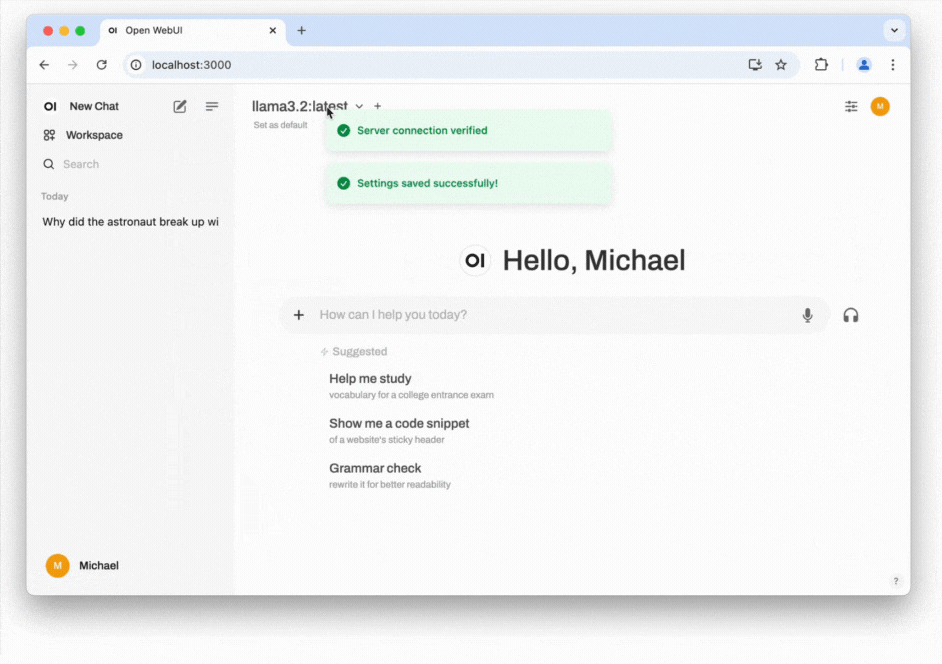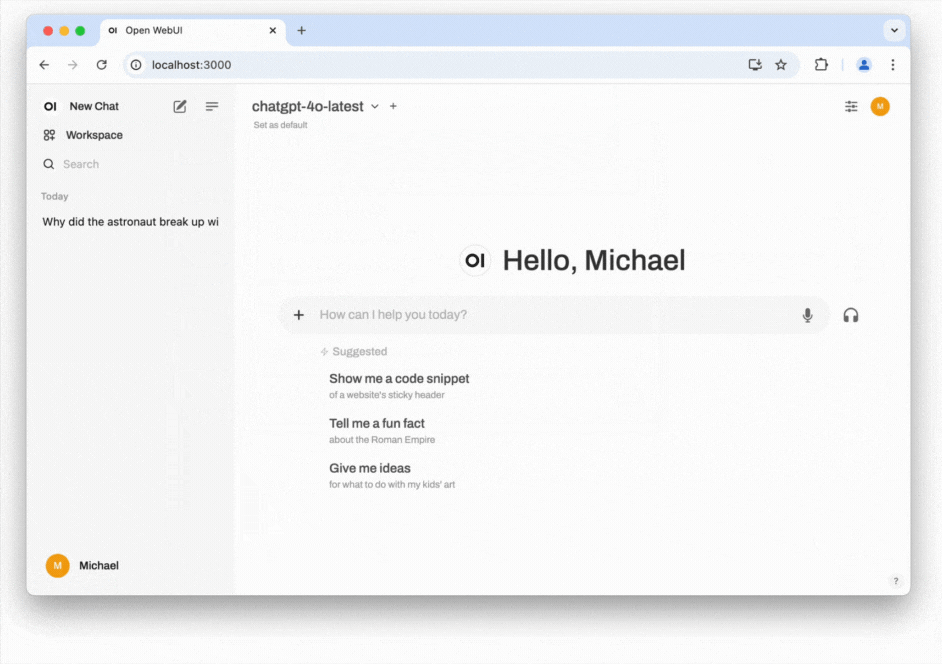
- Optional - add ChatGPT: You can easily switch between local models and ChatGPT. To do so, you'll need an OpenAI API key, which can be obtained by registering with OpenAI. Please note that using the API will incur costs on a pay-per-use basis and will transmit data to OpenAI. According to OpenAI, this data will not be used to train their model. Once you've acquired the API key, go to the Admin Settings, click on the Connections tab, enter the key, and click Save. After that, you'll be able to see all the available OpenAI models in the dropdown menu. If you’re paying for API usage, you might want to consider cancelling any existing monthly subscription with OpenAI to avoid duplicated costs.
How to compare models
Another great feature of Open WebUI is the option to easily get responses from various models to compare their performance or select the most suitable option from multiple responses.
To enable this feature, simply click on the plus sign next to the model selection and choose one or more additional models. Additionally, you can save your selection as the default option, ensuring that you always have access to multiple responses.
Conclusion
Running ChatGPT-style AI models on your own computer is now more accessible than ever with tools like Ollama. This allows you to harness the power of large language models offline, ensuring greater privacy by keeping your data on your device. Thanks to quantisation, even standard computers can now manage these models without the need for expensive hardware or cloud services. This shift benefits individuals and corporations with strict privacy requirements, while also highlighting how LLMs are becoming commoditised. Most of the value in the AI space is increasingly being generated at the application layer.
While setting this up may feel a bit technical for some users, simpler installation options are likely to emerge soon. When comparing responses from downloaded models with ChatGPT, it becomes clear that larger models with additional functionality—such as advanced fine-tuning, moderation tools, safety mechanisms, or context management, as seen with OpenAI's enhancements—result in slightly more refined and accurate responses. However, as technology evolves, this gap may soon narrow.



